Mix-IT 2014
28 Apr 2014
Le Mix-IT est une conférence, sur Lyon, accessible à tous, sur l’agilité, l’écosystème Java et les innovations IT, Web ou mobile. L’édition 2014 a eu lieu le 29 et 30 avril 2014 à CPE Lyon et avait pour thème “Des idées pour tout de suite !”.

A chaque début de demi-journée, les speakers montent sur scène pour pitcher leur conférence. C’est une excellente idée pour permettre aux participants de bien choisir ce qu’ils vont aller voir.
Et si nous n’étions qu’au début ?
Keynote assurée par Lionel Dricot, alias Ploum. J’aime beaucoup ce blogueur.
Slides disponibles ici.
Le speaker nous explique que nous vivons dans une société capitaliste, où tout le monde court après l’argent mais que malheuresement pour être riche il faut l’être déjà avant. Les sociétés se rachètent entre elles pour supprimer petit à petit la concurrence. Les gens ont tendances à être conservateur. Cela peut se comprendre. Quand on est en haut de la pyramide, personne n’a envie de redescendre ou de changer quoi que ce soit. Ce problème de concentration rabaisse l’innovation dans certains secteurs à un niveau proche de 0.
Je suis tout à fait d’accord avec lui sur le fait que les startups sont les maîtres d’oeuvre de l’innovation et de gros changements vont bouleverser la société…
Pour illustrer ses propos, il nous explique comment le Bitcoin fonctionne, comment il peut remettre en cause l’économie d’aujourd’hui. Contrairement aux autres devises monétaires le Bitcoin n’est pas géré par un état, une banque ou une entreprise. Sa valeur est donnée par l’usage économique qui en est fait. Les participants forment un réseau peer-to-peer via Internet. Le Bitcoin est un exemple de “Rewrite from scratch” de la monnaie.
Il nous explique ensuite comment appliquer le même principe à tout un tas d’autres domaines de la société : élection, impôts…
J’ai vraiment aimé cette keynote et je ne pense pas que les idées énoncées soient si folles que ça. Qui aurait cru, il y a 10 ans, à l’explosion des smartphones, à un monde mobile et ultra-connecté ?
Des petits pas vers le Continuous Delivery
Conférence donnée par Dimitri Baeli et Arnaud Pflieger de lesfurets.com.
Slides disponibles ici.
Quelques chiffres sur leur équipe,
- 16 développeurs
- 2 quality engeneer
- 1 ops
- 1 archi-codeur
- 2 features teams
- 1 component team
Quelques chiffres sur le site,
- 1 site front
- 1 bo
- 10 serveurs
- 1 code base
- 300k loc
- 30k tests
- 200 tests selenium
En 2012, ils étaient en SCRUM avec des sprints de 6 semaines. Ils utilisaient subversion (trunk + branche de prod). Ils leur fallaient 30 minutes pour un build, et les tests selenium prennaient 1h. Une seule MEP par mois était faite et elle durait 1h30.
En 2014, ils sont en KANBAN. Ils utilisent git (master + 30 branches). Il leur faut 3 minutes pour un build et les tests selenium prennent 10min. Ils font une livraison de ce qui est prêt à j+2 et une MEP prend 6 minutes.
Pour eux,
- Cycle d’une story : inception (idées) -> analyse (objectifs) -> construction (développement, validation) -> livraison -> monitoring
- Cycle de développement : implémentation -> intégration -> tests -> validation -> livraison -> mep -> exploitation
Ils nous donnent un très bon conseil : l’amélioration continue doit commencer par la fin pour garantir une prod OK et des étapes avales qui ne coincent pas.
Ils ont donc commencé par améliorer leur exploitation. Ils ont mis en place un Zabbix pour le monitoring système mais aussi applicatif et métier. Ils ont implémenté un tas de sondes dans le code pour chaque fonctionnalité. La gestion des erreurs et des logs est un boulot à temps plein. Les logs étaient envoyé par mail, puis ils ont mis en place un graylog. L’astreinte est assurée par l’équipe 24/7.
Ils ont ensuite amélioré leur mise en production. C’est un évènement risqué et il faut absolument le simplifier, le sécuriser et l’automatiser au plus tôt. La configuration applicative est gérée par le code et n’est plus gérée lors de la MEP pour éviter toute erreur humaine. Ils utilisent la technique du Blue/Green deployment (environnement de production dupliqué, loadbalancer en entrée).
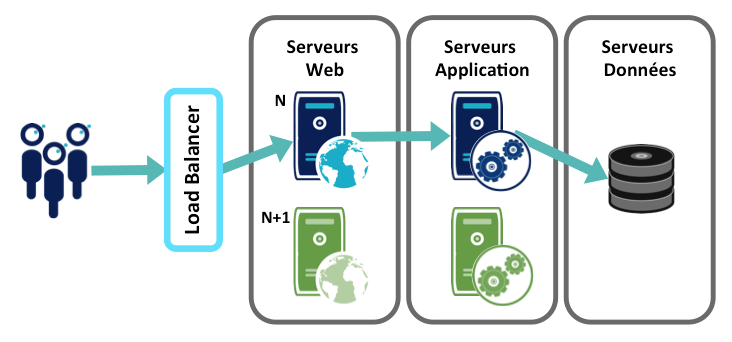
Ils ont amélioré leur livraison. Ils travaillent par pull request. La livraison est faite par feature : nouvelle fonctionnalité, bugfix, changement de conf, … Les branches finies passent en production. Rien n’arrête la MEP. Ils soulèvent le problème des PR : les conflits entre les branches. Ils proposent la solution d’une branche octopus pour lancer les tests automatiquement sur les serveurs d’intégration continue : merger toutes les branches de développement pour les tester ensemble d’un coup.
Ils ont amélioré leur système de validation. Ils font pas mal de code review. Ils nous expliquent que l’équipe a une énorme capacité de test naturelle (multi navigateurs, multi devices). Ils mettent en avant un autre problème des PR : l’isolement et l’entrave à la capacité naturelle de test. Tout est automatisé et outillé par selenium.
Ils ont amélioré leur PIC. Elle s’occupe de la compilation, des tests automatisés et des merges automatiques.
Stratégie de merge : octopus (permet de construire l’env de test (dev), facilité la livraison et faire ressortir les conflits sans bloquer les autres).
Ils travaillent énormément sur cette partie depuis le début de l’année. Une intégration continue rapide est une obligation.
La gestion des conflits est géré par le codeur de la feature.
C’est lui qui s’occupe de mettre les fichiers dans le même état grâce au cherry-pick ou à des recopies manuelles.
Autre solution : merge entre les branches mais cela impose une dépendance entre des features et est donc à éviter.
Dommage, il n’y a pas eu le temps pour des questions / réponses.
Toyota Kata
Conférence donnée par Hakan Forss.
Slides disponibles ici.
Il commence sur cette citation que j’ai beaucoup aimé.
We are what we repeatedly do. Excellence, then, is not an act, but a habit. Aristotle
Un Kata est un terme japonais issu des arts martiaux.
Il s’agit de mouvements codifiés à partir de l’expérience de combattants dont les noms ont été perdus. Les katas sont par la suite devenus des outils de transmission de techniques, mais aussi de principes, de combat. wikipédia
Le Toyota Kata permet de mettre en place des automatismes, de “se muscler la mémoire” afin de s’améliorer.
Il se résume par 3 phases :
- Phase de plannification :
- comprendre la direction
- comprendre l’état actuel
- mettre en place des objectifs
- Phase d’exécution :
- Essayer et ré-essayer jusqu’à se rapprocher le plus possible de l’objectif
- Répéter !
Il ne faut pas sous-estimer les expérimentations et les résultats obtenus.
I didn’t expect that! The sound of discover
Il nous a fait faire un exercice durant lequel on devait croiser les bras une première fois et ensuite on devait chercher une nouvelle façon de croiser les bras. Le sentiment dégagé est étrange pourtant ce sont les mêmes bras et le même cerveau.
50% des expérimentations ne vont pas donner le résultat attendu.
La phase d’exécution peut être résumé en 4 étapes :
- Hypothèse
- Prédiction
- Expérimentation
- Observation
L’apprentissage est la résultante de la comparaison entre la prédiction et l’observation.
On se met des challenges à atteindre dans 2 mois, 6 mois, 1 an… Entre chaque défi, on prend conscience de comment est la société maintenant.
Deux notions sont importantes dans le Toyota Kata :
Improvment Kata : l’amélioration continue.
Comprendre la direction : On doit être d’accord sur la vison de la société.
Une vision n’est pas forcément atteignable mais quelque chose vers lequel on peut tendre.
Chez Toyota, l’objectif est : 0 défaut, sécurité, 100% de valeur ajouté, création à la demande.
Méthode “Lean” : on reste focus sur le process et le produit est le résultat du process. On écarte la vision business.
Pour rester concentrer, on doit collecter des données factuelles. On écarte les données affectives.
Métriques utiles :
- temps pris pour effectuer une action
- le nombre d’actions effectuées en un temps donné
- la qualité du produit final
Une fois un objectif atteint, on passe sur l’objectif suivant. Il doit rester atteignable et pas complétement fou afin de rester motivé.
Il faut effectuer des baby-steps ! La problématique va évoluer jusqu’à l’atteinte de l’objectif.
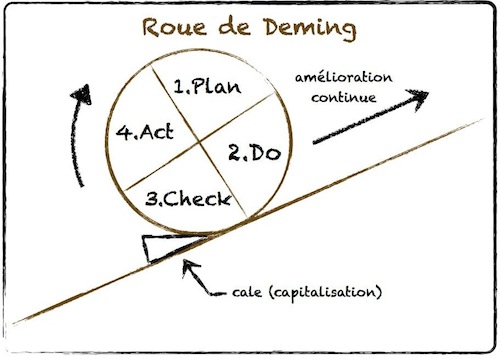
Coaching Kata : le leader qui organise et supporte ce travail.
Il est indispensable ! C’est un facilitateur. Il doit aider à rester focus sur l’apprentissage.
Les 5 questions qu’il doit toujours poser à l’équipe lors du franchissement d’un objectif :
- Quelle est l’objectif à atteindre ?
- Quelle est la condition actuelle ?
- Quels sont les obstacles qui nous empêche d’atteindre le prochain objectif ? Sur lequel on se focus actuellement ?
- Quelle est la prochaine étape ?
- Qu’est-ce qu’on a appris en franchissant cette étape ?
Le go & see est très important. On essaye, on voit, on apprend.
Les améliorations sont des expérimentations. Il faut mettre en place des routines pour nous aider à franchir l’inconnu.
Ouvrage de référence sur le sujet :
- http://www.lean.org/kata
Google Glass
Conférence donnée par Alain Regnier.
Les Google glass embarquent un Android ICS 4.0.4. Les glass disposent :
- d’un transducteur à conduction osseuse : permet d’entendre du son sans transmetteur, fonctionne par vibration
- d’un capteur de proximité, de lumière ambiante, infrarouge
Les évènements sont gérés grâce à une timeline : du plus récent (à gauche) au plus ancien (à droite).
Les contrôles commencent par : “OK, Glass”, suivi d’une commande.
Que peut-on faire ?
- prendre une photo / vidéo
- faire une recherche google
- demander des directions
- recevoir des mails
- appeler un contact
- participer à un hangout
L’application “MyGlass Mobile” permet d’accéder aux lunettes via smartphone.
Exemples d’applications existantes pour les glass :
- NYT Glass
- CNN Glassware
- Spellista (jeu)
- Translate (impressionant !)
Les glass ne sont accessibles pour l’instant qu’aux personnes ayant adhérées au programme “Glass Explorer”. Uniquement accessible aux américains. 8000 personnes ont été sélectionné.
3 techniques de programmation possibles :
- Mirror API (prog côté serveur en Python, Java, Ruby, PHP) : RESTful services, Authentification OAuth 2.0, Pas besoin de code sur les Glass
- GDK (Glass Development Kit, sneak Peek v1 le 19 novembre 2013) : dev Android avec un simple add-on pour accéder aux commandes de base
- WearScript : Javascript pour Google Glass (écrit par Brandyn White)
https://developers.google.com/glass / @GlassFrance
Tour d’horizon de Node.js
Conférence donnée par Christophe Porteneuve.
Slides disponibles ici.
La conférence n’était pas du tout technique. Elle était là pour rappeler que Node.js est une solution fiable et performante. C’était aussi l’occasion pour le speaker de troller à tour de bras Java, PHP, Ruby… Bref, c’était rafraîchissant.
Un peu d’historique :
- 2009 : annonce officiel (Ryan Dahl (qui n’aimait pas JS)) à JSConf.EU
- 2013 : utilisé en production par eBay, LinkedIn, Walmart, Groupon, Yahoo! …
- Aujourd’hui : 70K+ modules, supporté par la majorité des PaaS (Joyent, Nodejitsu, Heroku)
Quelques références :
- http://delicious-insights.com:8080/front
- https://github.com/tdd/node-demo
- http://nodeschool.io
- http://nodestreams.com/
- https://www.codeschool.com/
- http://howtonode.org/
- http://nodetoolbox.com
Bien choisir son serveur de message
Conférence donnée par Guillaume Arnaud.
Quand utiliser des serveurs de message ?
Les serveurs de message sont utiles pour : Worker, RPC, Log, Dashboard, Synchronisation, Metrics.
Première mise en garde : Attention au broker de message qui tombe, cela entraine des pertes de messages. Il faut également penser au limitation des queues de message.
Comparaison entre différents serveurs de message :
- JMS donnent la possibilité de faire
- Queue : CBA (consumer 1 : A, consumer 2 : B, consumer 3 : C)
- Topic : CBA (consumer 1 : CBA, consumer 2 : CBA, consumer 3 : CB)
- AMQP
- ne pas avoir peur de créer plein de queue
- mode : fanout (broadcast de message), direct, topic, headers (suivant certaines règles, on peut choisir la queue qui va bien)
- STOMP (light messaging)
- très bien pour démarrer dans le messaging. Ultra-simple.
- heartbeat : très pratique pour connaitre les ruptures de serveur
- MQTT
- orienté device mobilité
- gère beaucoup de contraintes : déconnexion, peu de réseau, …
- possibilité de retenir des messages
- très minimaliste (2o de header) contrairement à JMS
- différents niveaux de QoS : 1 (au mieux, un message délivré), 2 (au moins, un message délivré), 3 (exactement un message délivré)
- Kafka, le préféré du speaker)
- utilisé par LinkedIn
- http://kafka.apache.org/
- Client Ruby : https://github.com/bpot/poseidon
- s’appuie sur Zookeeper
Autres solutions : RabbitMQ, Redis (notion d’inscription à des queues), Flume (centralisation des logs)
How to rewrite your JavaScript app ten times
Conférence donnée par Garann Means.
Slides disponibles ici.
Vous avez besoin d’un planning de rewrite, pas d’un nouveau framework, pas d’un nouveau système de template, …
La speakeuse met beaucoup en avant les problématiques que l’on rencontre en tant que dev mais ne propose pas beaucoup de solutions.
Je n’ai pas retenu grand chose de cette conférence.
Le Web est la plateforme (mobile)
Conférence donnée par Tristan Nitot.
Le speaker met beaucoup en avant Firefox OS et vente les avantages par rapport à Android ou iOS.
Il nous explique que, sous Firefox OS, nous n’avons pas besoin d’apprendre un x-ième langage. Il suffit juste de savoir faire une minimum de développement web (HTML5, CSS3, JS).
Je n’ai pas appris grand chose mais ce genre de discours fait toujours du bien à entendre quand les débats dans les entreprises tournent autour d’applications web vs. applications natives.
Des produits avec des équipes distribuées ?
Conférence donnée par Alexis Monville.
Alexis est un OpenStacker.
Sa conférence est basée sur un retour d’expérience de la gestion de la communauté d’OpenStack :
Ils mettent en place des Release Cycle : Planning, Implementation, Pre-release, Release. Cela permet de focaliser les gens sur le même objectif. En phase de pre-release, il est important que tout le monde se concentre sur les bugs bloquants.
Un développeur occupe le poste de PTL (Project Technical Leads) qui tourne tout les 6 mois. Il y a 1 PO par équipe.
Il est indispensable d’avoir des sessions de travail physique une fois de temps en temps (par mois, tous les 6 mois, …) afin d’assurer de la cohérence, la vision du produit.
Le code soumis par PR ne peut pas être mergé par une seule personne. Pour que la PR soit mergé, il faut au moins un vote positif de 2 core-developers. Les Core-developers sont élus par les core-developers. On devient core-developer en étant uniquement un bon développeur !
La qualité des retours sur les PRs vont faire en sorte que l’équipe est de qualité et que le projet aussi : https://review.openstack.org/
Il utilise Zuul (gatekeeper). Il permet de faire tourner les tests automatiquement pour être certain que le code ne casse rien.
Leur gestion des branches est à regarder car très intéressante.
Scaling up Twitter systems
Conférence donnée par Ity Kaul.
Twitter, c’est :
- 35+ languages
- 255 millions utilisateurs par mois
- 500 millions tweets par jour
Un peu d’historique :
- 2010
- 3283 tweets/s
- Monorail! (Monolithic Ror app) + MySQL + Cache : 200~300 req/s
- 2013
- 143199 tweets/s
- Towards distributed system
- Java / Scala (with small services) / Finagle / Zipkin